
過往蒐集完文本資料時,需先經人工標記,再由程式進行分析、統計,既費時又耗力,但現行已可使用機器在沒有字典比對之下,利用語意、句法分析,和上下文的字詞出現頻率,如同人類似的經學習演算法,機器可自動標記人事時地物,不但能處理大量的資料,且可維持一致性,不因人工標記而造成偏誤。例如下圖中,即便是外國人名,或是罕見的姓氏,機器仍是能精準的辨識出來。

▲意藍資訊之人名標示準確度高達99.7%
若要客製訓練機器識別、分類某領域之文字時,需準備若干含有數個子議題的範本,機器會藉由學習為數不等的文本,歸納出分類與標記的邏輯;意藍資訊自己本身已建有一些常用的標記,如立場(支持/反對)、價格等,另外還和學界一同合作,標記十幾萬篇的文本,歸納學習出可應用在各界的通用模型,創建了目前最大的中文繁體情緒語料庫。
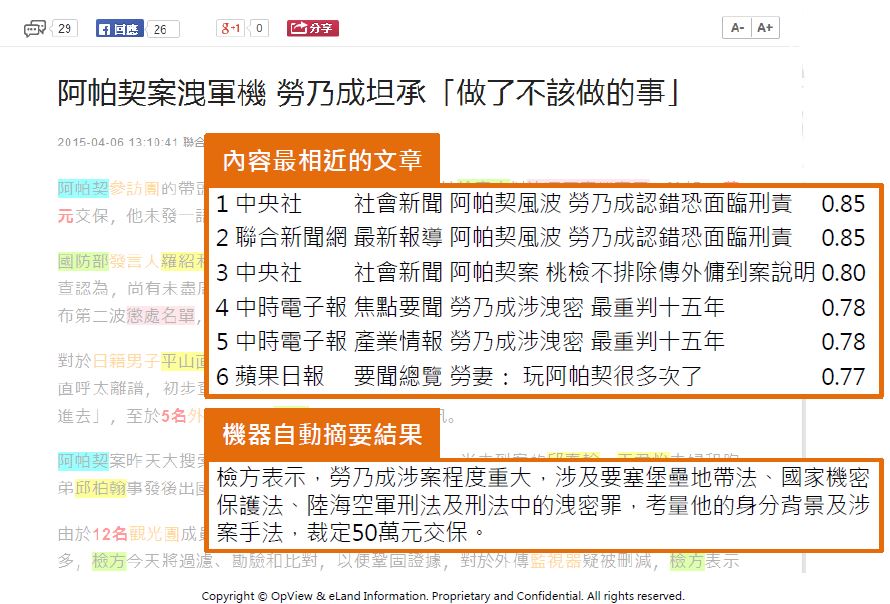
完成標記後,利用全文比對技術,可找出數篇文章之間的相似性,並由電腦自動計算相關性,使用此技術,在學術界還可製作出遏止抄襲的比對程式。
除此之外,在大量文本待處理的繁雜程序上,也可由機器爬文,藉由文法邏輯與重複率等演算,計算出字句重要性,最後自動產出簡要文摘。在國外,已有報社利用此技術,使用機器自動摘錄並產出大量新聞稿,堪稱機器記者時代的濫觴。
這些處理文本的技術,已漸漸應用在社群、客服、市調部門,以便快速處理企業內部資訊,加速了解顧客的反饋;甚至在國家警政上,過去意藍資訊曾協助刑事警察局資訊中心,處理累積多年之刑案資訊,其中包含多種來源與資料格式,跨文件的分析在一開始就顯得困難重重,但在進行資料整備、匯入,藉由機器標記及分析,導入知識工程技術後,要進行傳統結構性資料的分析,就顯得容易多了,不論是再輔以R或是Excel的樞紐分析等統計軟體,皆可快速的做出視覺化的圖表。
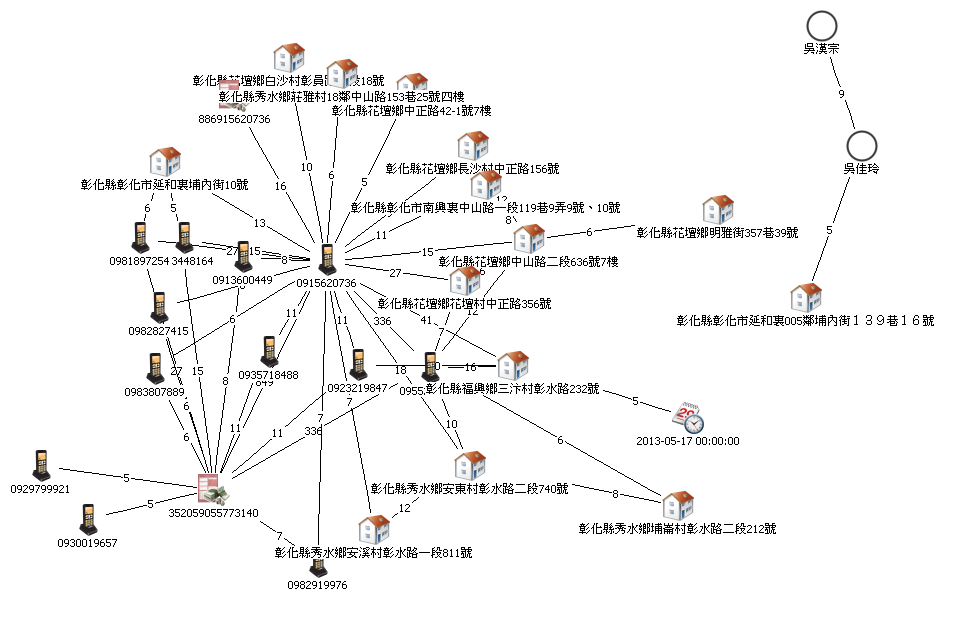
▲標記完後的資訊,可快速產出犯罪關聯圖
雖然內部擁有來自顧客、會員的豐富資料源,然而許多企業仍渴望更多的外部資訊,傳統的街訪或電訪是常見的取得外部資料的方式之一,但在分分秒秒快速變化的商業競爭中,傳統的取樣法不但耗時,所得的樣本母體也不一定能符合實際狀況。

受到國外資料應用的啟發,意藍資訊自2012年起開始建立龐大的輿論資料庫,收取範圍參考Alexa、《數位時代》歷年熱門網站排行等知名公信榜單,由網路機器人巡邏各大網路頻道,最慢在35分鐘至40分鐘後即會將文章抓取進資料庫,日進量超過60億字,加之情緒標記的技術已成熟,可以快速判讀文章立場,因此進行長時間的的議題研究時,要比傳統的市調要容易的多,特別是涉及隱私,眾人不願在面對面的情況下吐露真言的社會議題,更是能迅速而精確的掌握人們的偏好態度。
最後,假如發現調查做得不完美,可能被迫要再用已經花費的時間及金錢去重複整個研究,然而使用社群聆聽法,通常可以更容易地重做研究中的一個部份,例如:增加問題及選項,只需要重新將資料中的一個部份編碼,而不是重做整個研究,對於學術研究而言,不但便利也更經濟。